rvm�˅������z���㷨��������
�1��2�����F��1��Ѧ���h2
l�������I��W���܌WԺ���������710032��2�������I��W�Ԅӻ��WԺ���������710072
ժ Ҫ���˺����ą�������Ӱ�rvm�ľC�����ܡ������ϡ��⡢�����^�M�ᣬ���ʹ���z���㷨ᘌ����}�����ԄӃ����˺����ą��������m���Ⱥ����u���£��NȺ���^�x�����׃���x���M������Ч�ʵصõ�****�⣬�ڶ��xrvm�ؚw���ܾC���u������fitness�����m���Ⱥ����Ļ��A�ϣ�ʹ��11atlab�z���㷨��������M��tipping����@ȡslne����****�˺�������������C���z���㷨���Ը�Ч�ʂ����rvm�˅������e���ھ����^�������ĺ˺������ߌ����ԡ�
�P�I�~���P�����C���˺����������C���u�И˜ʣ��z���㷨
�ЈD���̖��tp 27 �īI���R�a��a
1����
rvm���P�����C����michael e tipping��2001�������һ�N������֧�������C( svm)֮�ϵ�ϡ��ؐ�~˹�yӋ�W������������Ӗ������ؐ�~˹������M�еģ����������M�лؚw�����ģʽ������rvm�˷�svmȱ�c��rvm���P������Ҫ����svm�����и����ķ������ܣ����Եõ��c��Ӌ���^�g��Ӌ���o����ԇ��ҵ�****�������c��s�����^�O��ֵ���csvm��Ƶ���rvmҲʹ�ú˷���������׃��ӳ�䵽�߾S���g���õ���׃���c��׃�����Իؚw��ϡ��⣬���˺�����������Ӱ�rvm�����ܣ���η����ݵ��ҵ��C������****�ĺ˺�������Ŀǰ�Пo��������Փָ��������rvm�ķ���ܽ����ڻؚw�Ļ��A֮�ϣ�Ŀǰ��rvm�㷨��ģʽ�R�e���ؚw��Ӌ�������ܶȺ�����Ӌ�ȷ����ЏV�����á����磬��ģʽ�R�e���棬�����������R�e���Z���R�e����Ę�D���R�e�����·�Ȇ��}�����ćLԇʹ���z���㷨�@ȡ�ؚw�C������****�ĺ˅�����ֵ�⡣
2 rvmģ��
�yӋ�W����Փ��һ�N���T�о�С�ӱ���r�C���W��Ҏ�ɵ���Փ��ԓ��Փᘌ�С�ӱ��yӋ���}������һ���µ���Փ�wϵ�����@�N�wϵ�µĽyӋ����Ҏ�t���H���]�ˌ��u�����ܵ�Ҫ�������ڬF��������Ϣ�ėl���µõ�****�Y����ģʽ�����о���������Ԅәz�y�ͱ��R�����Н��ڵ��Pϵ���� 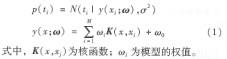 �鱣�C�@ȡϡ��⣬����M�����ֵ���B�ֲ���p��wi����i��=n��wi| 0����i-1����Ӗ���ӱ�������Ȼ������
���������ʷֲ�����Ȼ�ֲ�������ؐ�~˹ʽӋ���ֵ�ĺ����ʷֲ�������
��ԓ��ֵ�ĺ��ֲ����ڶ�׃����˹�ֲ�������
Ӗ��Ŀ��ֵ����Ȼ�ֲ�ͨ�^����ֵ׃���M�зe�֣���
���F߅�������Ķ���ó�������߅����Ȼ�ֲ���
rvm�����е�ģ�͙�ֵ�Ĺ�Ӌֵ�ɺ��ֲ��ľ�ֵ�o����ͬ�r��Ҳ�Ǚ�ֵ��****���( map)��Ӌ����ֵ��map��Ӌȡ�Q�ڳ��������������Ӌֵ���ͦ�2����ͨ�^****��߅����Ȼ�ֲ��õ������ֲ���ӳ���ę�ֵ****ֵ�IJ��_���ԣ����Ա�ʾģ���A�y�IJ��_���ԡ����o��ݔ��ֵx������ݔ���ĸ��ʷֲ���
���ĸ�˹�ֲ�����ʽ������
3 rvm�ؚw�����c�˺�������
tipping�õڶ�O����Ȼ���o����matlah���������ڴ˻��A��չ�_�о����o��һ���˺�һ��Ӗ�����ϣ����ܘ���һ���˾��k(xi��xj)���@�����������Ϣƿ�i�����ã������ |