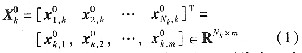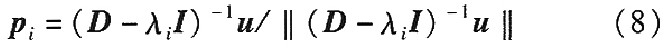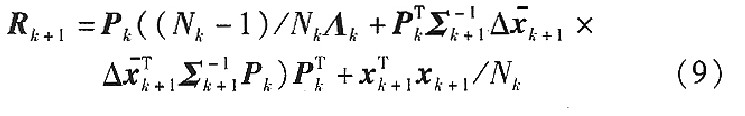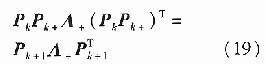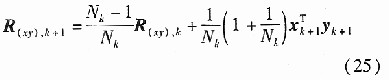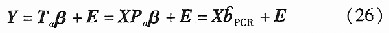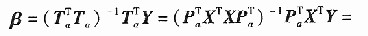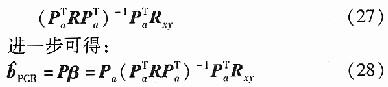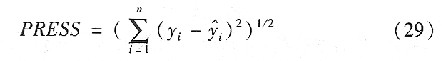���M���f����Ԫ�������f����Ԫ�ؚw�㷨
������������
(���A��W�Ԅӻ�ϵ������100084)
ժ Ҫ�����˼���ģ���ھ����µ��ٶ��Ը��õ��m�����H���I�^�̵ĄӑB׃����ͨ�^�������f����Ԫ����(PCA)�㷨�Ļ��A�Ϻ����������P��ꇵ��f�ƹ�ʽ���Ķ����M�˻�����1���µ��f��PCA�㷨����ԭ����Ҫ�M��2����1���µIJ��E������H�H��Ҫ�M��һ����1���£����ڴ˻��A��������f����Ԫ�ؚw�㷨������Y�����������M��Ļ�����1���µ��f��PCA�㷨��ԭ���Ļ�����l���µ��f��PCA�㷨�s���˽�һ����\��r�g�����µ��f����Ԫ�ؚw�㷨�������܉��m�����I�^�̵ĄӑB׃�������ұ���̎���ķ�ʽ���s�˴惦���g�cӋ��r�g��
�P�I�~���f����Ԫ�����������Pꇣ���1���£��f����Ԫ�ؚw
�ЈD���̖��TP 27 �īI���R�a��A
Improved Recursive PCA a nd Recursive PCR Algorithms
CHENG Long��WANG Gui-zeng
(Department ofAutomation��Tsinghua University��Beringl00084��China)
Abstract��To accelerate the model 0n-line modificatlon a nd accommodate the industrial process change��an efficient recursive PCA al-gorithm using rank-one modification a nd a novel recursive PCR algorithm are proposed by improving the approach of updating correlationmatrix Simulation resuits show that the improved recursive PCA based on rank-one modification shotren the computational time in con-trast with the existing recursive PCA algorithm Moreover��the recursive PCR algorithm Call adapt process changes a nd need less corn-puting time a nd memm?usage than batch PCR algorithm
Key words��reellisive PCA��coneiation matrix��rank-one modification��recursive PCR
1����
��Ԫ����(PCA)��һ�N���������P׃���D�����ٔ��ׂ������׃���ĽyӋ����������
��Ԫ������Pearson[1]�����������Hoteling[2]���Ը��M����Ԫ�������Ԍ��ܶ����P�^��׃�����s���ٔ�������׃������˱��V���������^�̱O��[3]�������\��[4]���I��
���H�Ĺ��I�^��ͨ�����F���r׃���ԣ�����Ԫ������������ģ���S���r�g�����ƌ����F���@��ƫ���ˣ��輰�r��ģ���M�и��£���������Ì��������f�����Y�������M����Ԫ������Ӌ�����ܴ�ᘌ�������r��Wold�����ָ���ә�ƽ����Ԫ�����ķ���[5]��Rigopoulos������˻��Ӵ��Y����Ԫ�����ķ���[6]����Liw H��������f��PCA�㷨[7]����������ꇵľ�ֵ���˜ʲ��M���f�Ƹ��£��Ķ��f�����Ҏ������Ĕ�����ꇣ��M���ó������Pꇵĸ��¹�ʽ�����������1���µó�ؓ�������͵÷�������
����ᘌ�Li WH��������f��PCA�㷨�������������Pꇵ��f�ƹ�ʽ�����M�˻�����1���µ��f��PCA�㷨�����o����ݔ��ݔ��׃���f�����ꇵ��f�ƹ�ʽ�������һ�N�µ���Ԫ�ؚw�f���㷨(PCR)�����挍��C���˷�������Ч�ԡ�
2���M���f��PCA�f���㷨
1)������1��н���f��PCA�㷨���xȫ��k��ԭʼݔ�딵���K�M�ɵľ�ꇞ�
���У�ÿһ�д���һ���ӱ���ÿһ�д���һ��ݔ��׃����
ȫ��(k+1)��ԭʼ�����K�M�ɵľ�ꇞ�Xok+1��ʽ�cXok��ͬ����ǰK�������K�L�Ȟ�Mk�����]ÿ�ɘ�һ���M��һ���f�ƣ��t�����픵��������(k+1)�������K���L�Ȟ�Nk+1=Nk+1��Weihua Li Hָ��[7]��ÿ������x0k+1��r�������f��Ӌ���ԭʼݔ�딵������и�׃���ľ�ֵ���˜ʲ��Ҏ�������ݔ�˔�����ꇣ��M���ó������Pꇵ��f�ƹ�ʽ��
��ֵ�������f��ʽ��
�������f��ʽ�У� 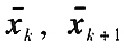 �քe���f��ǰ���ֵ�������Ҟ���������ÿһԪ�؞錦��ݔ��׃���ľ�ֵ�� 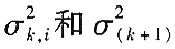 i�քe���f��ǰ���i��׃���ķ�� 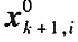 ���픵������ 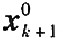 �ĵ�i��Ԫ�أ�R�� 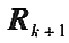 �քe���f��ǰ��Ҏ������ݔ�˔���ꇵ������P��ꇣ����]Ҏ��������픵������ 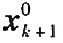 ���ݔ����׃���ľ�ֵ������������D--- ʽ��, 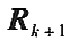 �錦���,���Ǿ�Ԫ�؞�di(i=1,2,...,m),�Ş鳣��. �����C��[8],����m���������ʽ��m���������ڸ����^�������P��ꇵ�m������ֵ��i��
����ֵ��i�������Ć�λ��������Pi����ͨ�^����Ӌ�㣺
Wemua Li H�Mһ��ָ����[7]������������1���µķ���������Rk�ѽ��ó�������ֵ������������Ϣ�Y�������Pꇵ��f�ƹ�ʽ�ó������^��ؓ�������c�÷�������
�Oǰһ�������P��������ֽ�ĽY����Rk=PkAkPTK�����У�PKÿһ�О��λ����������AK�nj��Ǿ�ꇣ����Ǿ��ϵ�Ԫ�؞�����ֵ������RK�錦�Q��ꇣ�����PK��������ꇡ�
��ǰһ�������P��������ֽ�ĽY�����������P��ꇵ��f��Ӌ��ʽ�еõ���
ʽ�У�Ak2�錦�Ǿ�ꇣ����Ǿ��ϵ�Ԫ�؞������^������ֵ��Pk+1=PKPK1PK2�����λ�����ÿһ�м�������^�ąf������RK+1����������(ؓ������)��
2)���M����1�����f��PcA�㷨���ڣ�
ʽ��,Pk+1=PkPk+1,��ÿһ�О�����^�����P���Pk+1�Ć�λ��������(ؓ������)��
�cԭ������l�����f��PCA�㷨��ȣ����M�^���㷨ֻ��Ҫ�M��һ����1���¾Ϳ������ؓ�����������s����Ӌ��r�g���Ҿ��Ȳ�׃��
3��Ԫ�ؚwPCR���f���㷨
1)ݔ��ݔ��׃���f����ꇵ��f��Ӌ�� ��PCR�У���Ҫ��ݔ�������Ҳ�M��Ҏ����̎��������ݔ������ꇵ���ʽ���£�
ͬ�ӿ��]ÿ��һ���������f��һ�ε���r������ݔ�딵����ꇸ������f��ʽ���ƌ����ɵ�ݔ��׃���ľ�ֵ�������f��ʽ��
ʽ��,  ��Ҏ��������픵��.���������P��ꇵĺ����f�ƹ�ʽ���ƌ�,�f�������Mһ���ɺ���: 2)�㷨������Ԫ�ؚw(PCR)��������׃��
���g�M�����ɷַ���(PCA)�������߾S���P��ԭʼ׃��ͶӰ���;S����������׃�����g�ϣ��ٽ�������׃��ͬݔ���g�Ļؚw�Pϵ��
�Oݔ��ݔ���Pϵ��
ʽ�У�a��ȡǰ������Ԫ������Ԫ�ؚwģ�͵ĵĻؚwϵ��������
��˲�������Ӌ��Ҏ�������ݔ��ݔ��׃���Ĕ�����ꇣ����H�H�f��Ӌ����׃���������Pꇺ���׃����׃���ąf����ꇾ��ܸ���PCR�Ļؚwϵ����
ע�⣬�@���b^PCR�nj���Ԫ�ؚwģ���D�Q����ԭʼ׃������ݔ��׃���r���õ���ƫ��С���˻ؚwģ�͵�ϵ��������������һ�����x�ϵ���ԭʼ׃������ݔ��׃���r����С���˻ؚwģ�͵�ϵ��������
�f��PCR���㷨�������£�
��ÿ��һ�M�������f��Ӌ��ݔ��ݔ��׃��������ꇵľ�ֵ���˜ʲ�M��Ӌ�������P�R�ͅf�����Rxy��
����R���f��ʽ������1�����f��Ӌ��ؓ��������
��ȡǰ����ؓ�������M��ؓ�������P����P����ÿһ�Ќ���һ��ؓ����������R��R��P������ʽ(28)�У�����PCRģ�͡�
�܌��˺����ӱ�(ݔ�˔���)�������µ�PCRģ�͌�ݔ���M���A��
�������f��PCR�㷨�У��H��Ҫ�惦ǰһ���f��Ӌ��ľ�ֵ�������˜ʲ�����Pꇡ��f����ꇣ����ô惦ԭʼݔ��ݔ������ꇣ�����ֵ�������˜ʲ�����Pꇡ��f����ꇵľS��ֻ�c׃���������P����˴��p���˴惦���g���S�������IJ������ӣ����������̎�����惦���g���������������f���㷨���惦���g�]��׃����
4 PCR����Y���c����
�����Ծ������a�нK�s�������ȵ�ܛ�y����ģ�����������f��PCA�㷨��ȡ�÷������cؓ���������ٽ�������������Ԫ�ؚwģ��(PCR)��������������ֵ�M�й�Ӌ��
�������Ǿ�����Ƭ����Ҫ���|��ָ�ˣ��DZ����������ą��������ھۺ���������c������Cе�����������Pϵ���ӹ���Ҫ�������������һ�������ȣ������a��Ҫ�������������׃�������������ǟo��ֱ�Ӝy���ą��������c�T���������P������K�s�۸����x�_��K�s�۸������w�����ȡ������ضȡ������������������D�١����������ڸ��ȵ�ͣ���r�g��������ȵȡ�
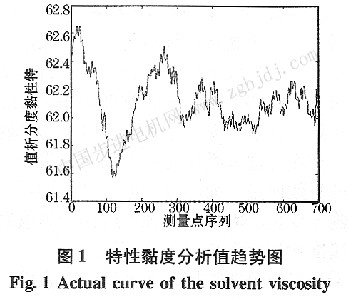
1)�����x���xȡ���B�m�r�g�Ό��H�y����700�M�����M�з��挍���У��xȡ10���c���������P��׃������ݔ�룬�������ȵķ���ֵ����ݔ����
��700�M�����֞�3�M��ǰ300�M���������ʼ��ģ���������g300�M������������������100�M��������yԇ������
�����ȷ���ֵڅ�݈D����D1��ʾ��
�ɈD��Ҋ��ǰ300�M�����������ȷ���ֵ׃�����^��(�����Hݔ����׃��׃�����^����)���ĵ�300�M�_ʼ�������ȷ���ֵ׃���^�龏��������Փ�ϣ��H�H��ǰ300�M�����������ģ���A�y���100�M����ֵ�Dz���ʴ_�ģ���횲����f���㷨����ģ�͡�
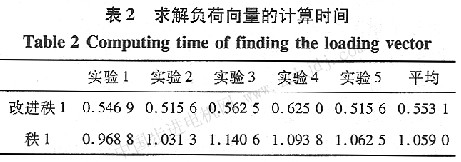
2)�f���㷨���\�Еr�g���^���f���㷨�У�������ȡǰ300�M��������Ԫ����PCRģ�ͣ�Ȼ����ǰ���ᵽ���f��PCR�������̣������g300�M�����M��PCRģ�͵��f��Ӌ�����õ��ĸ���ģ�͌���100�M�����M��ݔ����Ӌ�����cȡǰ600�M������PCR��̎���������õ�ģ���M��ݔ����Ӌ�ĕr�g�M�б��^���Y��Ҋ��1��
�ɱ�1��֪�������f�ƹ�ʽ���
����^֮��̎������������������������Ӌ��ģ�ͅ�����Ӌ��r�g�s�̽�2��3��
���ؓ��������Ӌ��r�g��Ҋ��2��
�ɱ�2���Կ��������M�^�Ļ�����l���µ��f��PCA�㷨�cԭ���Ļ�����1���µ��f��PCA�㷨��Ȝp��һ����l�����IJ��E��Ӌ��r�g�s���˼sһ�롣
3)�f��PCR�㷨�ĽY�����ȱ��^�f��PCR�㷨�����ڂ��yPCR�㷨��һ����Ҫ���c���ǿ��Ԍ��r����ģ�ͅ������Ķ�ʹģ���õ��m�����r��׃����ʹ��Ӌ�Y�����ʴ_��
2�Nģ�͌��yԇ��(100�M����)�M�й�Ӌ��ģ�͚���ƽ���͵ı��^��Ҋ��3��
��3�еķ��f��PCR�㷨�H��ǰ300�M�����M�н�ģ�������M�������l���µ��f���㷨��ǰ300�M����ģ�͵Ļ��A�������g�ģ�300�M�����M���f��Ӌ�㣬���@300�M�����ڌ��H�y���r�ஔ���픵����Ҳ�����f����ԭ����300�M�������A�Ͻ���������ģ���M���˸��£��䌍�ڌ��H���a�У�ֻҪ����һ�M�������Ϳ����R�ό�ģ��ʩ�и��£��M���ø����^��ģ���M���A�y��
�ɱ�3����֪���f���㷨����ģ�͵Ĺ�Ӌ���܃��ڷ��f���㷨�r��ģ�����ܡ�
5�Y�Z
���������е��f��PCA�㷨�Ļ��A�ϣ������������Pꇵĸ�н��ʽ�����M�˻�����1���µ��f��PCA�㷨���������һ�N�µ��f��PCR�㷨��
���挍�������f���㷨������ģ�Ȳ������f���㷨����ģ��ۙЧ��Ҫ�á����M��Ļ�����l���µ��f��PCA�㷨�����ڱ�����ԭ������1���µ��f���㷨�ľ��ȣ����ҿs����Ӌ��r�g���ڴ˻��A�ϵõ����f����Ԫ�����㷨�����H�܉��m���^�̵ĄӑB׃�����ұ���̎���ķ�ʽ���s�˴惦���g�cӋ��r�g��
|